Using INDEX_FFS To Recover Table Which has Corrupted Blocks
In this article, I will try to demonstrate how to recover data from your corrupted table.
This method will not always gurantee to recover 100% of your table but the aim is to give the idea how to recover your data as much as possible in some favorable conditions.
Off course there are some other methods like salvaging the table according to ROWIDs which are not around the corrupted blocks but in this article I will use INDEX_FFS (Index Fast Full Scan) to retrieve the data.
What is FFS? (from oracle docs)
An index fast full scan reads the index blocks in unsorted order, as they exist on disk.
This scan does not use the index to probe the table, but reads the index instead of the table,
essentially using the index itself as a table.
When the Optimizer Considers Index Fast Full Scans? (from oracle docs)
The optimizer considers this scan when a query only accesses attributes in the index.
To sum up, FFS will read the index to retrieve the data without accessing the table when the query asks only the columns which are exist on the index.
As I mentioned, this method will never gurantee to recover all data but I will write a scenario (tables, indexes etc.) to recover all my data.
Scenario:
Create Table;
create table hr.MY_EMP
(
employee_id NUMBER(6) not null,
first_name VARCHAR2(20),
hire_date DATE not null,
department_id NUMBER(4)
);
Create Primary Key;
alter table hr.MY_EMP
add constraint EMP_PK primary key (EMPLOYEE_ID) using index;
Create indexes;
create index hr.myemp_indx1 on hr.my_emp (employee_id,hire_date,department_id);
create index hr.myemp_indx2 on hr.my_emp (employee_id,first_name);
Analyze Table
begin
dbms_stats.gather_table_stats(ownname => 'HR',
tabname => 'MY_EMP',
cascade => TRUE);
end;
Load 100.000 random rows into my table
SQL> select * from hr.my_emp;

Check The Extents and Blocks
select file_id,block_id,blocks,extent_id
from dba_extents
where owner='HR'
and segment_name='MY_EMP'
and segment_type='TABLE'
order by extent_id;

Corrupt some blocks manually
dd of=/u01/app/oracle/oradata/TEST/users02.dbf bs=8192 conv=notrunc seek=1649992 << EOF
> corrupt block
> EOF
0+1 records in
0+1 records out
14 bytes (14 B) copied, 0.000294391 s, 47.6 kB/s
dd of=/u01/app/oracle/oradata/TEST/users02.dbf bs=8192 conv=notrunc seek=1650720 << EOF
> corrupt block
> EOF
0+1 records in
0+1 records out
14 bytes (14 B) copied, 0.00014643 s, 95.6 kB/s
Flush the buffer cache
alter system flush buffer_cache;
Now, try to select all rows and check sql plan

As you see above, I could select only 5400 rows until the first corrupted block if I want to select directly table
USING INDEX FAST FULL SCAN
Read the 1st index
*Sometimes CBO doesn't use FFS if you don't filter the query. To force the CBO to use the index, I'm adding a fake filter (e.employee!=-1) in the when condition
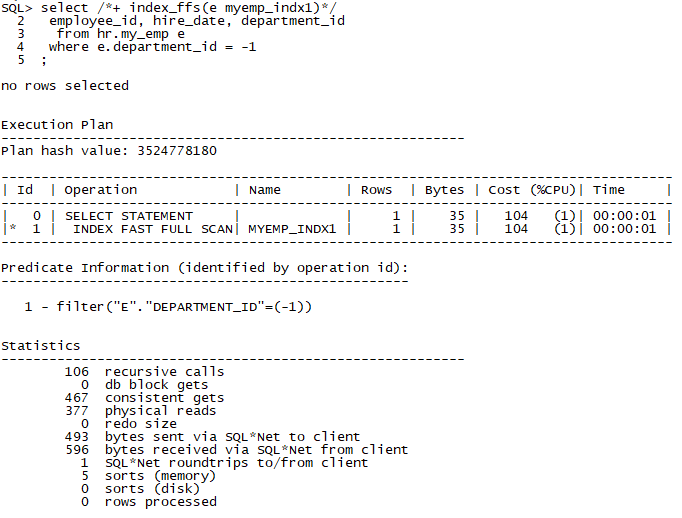
As you seee, I could select all 100000 rows without corruption. For now, I have full data of "employee_id", "hire_date" and "department_id" columns.
Read the 2nd index
*Using a fake index again (e.first_name!='XZYWQ')
*Using a fake index again (e.first_name!='XZYWQ')

As you see, I could read the 100000 rows for "first_name" column.
CREATE NEW TABLE
Now I can create a new table and load all data without corruption. My new table is on a new tablespace which doesnt have a corrupted datafile.
create table hr.MY_EMP_RECO
(
employee_id NUMBER(6),
first_name VARCHAR2(20),
hire_date DATE,
department_id NUMBER(4)
)tablespace tbs_reco;
alter table hr.MY_EMP_RECO add constraint EMP_RECO_PK primary key (EMPLOYEE_ID) using index;
RECOVER DATA
First, load 100000 rows of employee_id, hire_date and department_id by using 1st index

Then, update the table to load first_name column.

Now, my table is ready. I retrieved all my data without accessing corrupted table blocks.

Comments
Post a Comment